
[논문 리뷰]DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRF 본문
[논문 리뷰]DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRF
점핑노루 2021. 8. 10. 20:361. Introduction
Deep Convolutional Neural Networks(DCNNs) image classification, object detection 등의 전반적인 CV 분야에서 좋은 performance를 보여주는 데에 많은 영향을 끼쳤다. DCNN은 end-to-end 및 built-in invariance 성질을 지니고 있기 때문이다. 그러나 invariance는 semantic segmentation 같은 dense prediction task를 저하시킨다고 한다.
그래서 DCNNs을 semantic image segmentation에 적용시킬 때, 세 가지 challenge들이 존재한다.
1. Reduced feature resolution
2. Existence of objects at multiple scales
3. Reduced localization accuracy due to DCNN invariance
본 논문에서 설명하는 모델인 DeepLab system은 세가지 challenge들을 극복한다. 각 challenge들에 대한 자세한 설명 + 극복방법은 아래와 같다.
1. Reduced feature resolution의 경우, 계속되는 max-pooling 및 downsampling('striding') 때문에 발생한다. 만약 이 두 방법으로 convolutional layer들을 계속 통과시킨다면, 매우 작은 spatial resolution의 feature map이 출력될 것이다. 그 해결방안으로 DCNN의 마지막 max pooling layer들을 filter upsampling으로 non-zero filter taps에 "구멍"을 넣는 방식으로 진행한다. Upsampled filter들을 우리는 atrous convolution이라고 부르기로 한다. Atrous convolution을 통해 parameter의 개수나 연산량을 증가시키지 않아도 filter들의 view를 늘릴 수 있다. (이에 대한 자세한 설명은 아래에 있다.)
2. Existence of objects at multiple scales의 경우, 기존에는 원본 이미지의 크기를 여러 개로 rescaling하여 feature map의 크기를 합산하는 방식으로 이루어졌다. 하지만 연산 비용이 증가한다는 단점이 존재한다. 이를 극복하려 우리는 spatial pyramid pooling에서 아이디어를 얻는다. 여러 병렬적인 atrous convolutional layer들에 다른 sampling rate들을 대입하기로 한다. 그럼으로 인하여 물체를 파악하고 여러 scale에서 이미지를 파악할 수 있다. 이를 "atrous spatial pyramid pooling"(ASPP)라고 한다.
3. Reduced localization accuracy due to DCNN invariance의 경우, skip layer을 사용하는 방법도 있긴 하다. 그러나 DeepLab은 fully connected Conditional Random Field(CRF)를 도입하여 미세한 디테일을 파악한다. CRF는 semantic segmentation에서 class scores과 super pixel(같은 정보를 가진 점들의 집합)을 결합하기 위하여 사용되었다. DeepLab에서 사용할 Fully connected pairwise CRF는 연산처리가 용이하고, 미세한 디테일을 파악할 수 있다. 그리고 DCNN 기반 pixel-level classifier이랑 사용되었을 경우 performance가 SoTA로 증가한다.
어쨌든 실용적인 측면에서 DeepLab은 속도, 정확도, 간결성이라는 3가지 장점을 지닌 모델이다.
우리가 다를 "updated" DeepLab system은 초기 버전보다 개선되었다. 다양한 scale에서 물체를 segment할 수 있고, deeplab에 ResNet의 residual net을 대입하기도 하였다. 그리고 다양한 model variants를 통해서 여러 task에서 SoTA 결과를 얻었다.
2. Related Work
10년 전의 semantic segmentation은 주로 직접 제작한 feature에다가 boosting, random forest, support vector machine등의 flat classifier들을 사용하였다. Image classification task에서 Deep Learning이 사용된 이후부터는 semantic segmentation에서도 deep learning을 사용하고자 하였다. 그러나 semantic segmentation은 detection 및 classification을 모두 진행해야 했기에 이 두 task들을 합치는 것이 관건이었다.
Semantic segmentation에서 사용된 DCNN은 3개의 family로 나눌 수 있다. (크게 3가지 방식으로 사용되었음을 의미하는 듯하다)
1. 첫 번째 family는 bottom-up segmentation 및 DCNN 기반의 region classification을 진행한다. Bottom-up segmentation이란 하나의 객체 안에 여러 segmentation을 만들어 그것들을 합치는 과정을 의미한다. 그러나 error이 발생하면 극복할 수 없다는 치명적인 단점이 있다. 그림을 보면 bottom-up segmentation의 이해가 더욱 빠를 것이다.

2. 두 번째 family는 image labeling에 사용된 DCNN feature들과 독립적으로 얻은 segmentation을 결합하는 방식이다. 이 방식을 더욱 개선하기 위하여 skip-layer을 사용하거나, intermediate feature map들을 pixel classification 과정에 사용하거나, region proposal들을 사용하기도 하였다. 그러나 segmentation이 DCNN과 떨어져 있다는 점에서 premature decision(미숙한 결정..?)을 내릴 가능성이 있다.
3. 마지막 family는 DCNN을 사용하여 바로 category-level pixel label들을 추출하는 방식으로써, segmentation을 아예 배제해도 된다. 우리의 논문은 이 family를 따르며, 추가적으로 multi-scale pooling techniques 및 densely connected CRF를 사용하여 우수한 성과를 낸다. 본 모델은 모든 픽셀을 CRF 노드로 취급하고, long-range dependencies를 활용하고, mean field inference를 사용한다.
나아가 semantic segmentation에서 우수한 성과를 낸 모델들은 모두 본 논문에서 다루고 있는 Atrous Convolution과 fully connected CRF를 사용하였다. 해당 모델들은 구조적인 예측을 위한 End-to-End training을 하였고, superivision의 정도를 낮추었다. Atrous Convolution은 비단 semantic segmentation뿐만 아니라 object detection, instance-level segmentation, visual question answering, optical flow에도 사용하게 되었다.
또한 deeplab을 ResNet과 같은 더욱 정교한 image classification DCNN과 결합하였을 때 더욱 좋은 결과를 얻었다.
3. Methods
DeepLab 모델의 개형은 아래와 같다.

3.1 Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
※해당 문단은 Introduction에서 한 이야기다
DCNN으로 semantic segmenation을 진행할 때, DCNN을 fully convolutional하게 사용하면 성공적으로 해결할 수 있다고 하였다. 그러나 spatial resolution이 각 층마다 대략 32배로 주는 현상이 발생하여 feature map이 작아질 수 있다는 단점이 있다. 'Deconvolutional layer'을 쓰는 방법도 존재하지만, 추가적인 시간과 비용이 요구된다.
Atrous Convolution은 특정 층의 response를 원하는 해상도로 조정할 수 있다. 네트워크가 학습된 후 사용할 수도 있고, 학습과 동시에 진행될 수도 있다. 일차원의 signal이 주어졌을 때, 그 식은 아래와 같다.

각 기호의 의미는 아래와 같다.
y[i]: atrous convolution^2 output
x[i]: 일차원 input
w[k]: 길이 K의 filter
r: input signal을 sample하는 stride
이 때 r=1은 표준 convolution을 의미한다. 아래 그림을 보면 이해가 용이할 것 같다.

(a)는 sparse feature extraction으로써 r=1일 때, (b)는 dense feature extraction으로써 r=2일 때이다. (b)를 살펴보면 r=2로 설정하였기 때문에 사이에 0이라는 공백이 하나 생기고, stride = 1으로 유지되었기 때문에 receptive field의 값이 커진다.
2차원일 때 알고리즘의 연산의 예는 아래의 그림과 같이 이루어진다.

파란선으로 이루어진 알고리즘은 sparse feature extraction with standard convolution with rate r =1이며, 빨간선으로 이루어진 알고리즘은 dense feature extraction with atrous convolution with rate r =2 이다.
파란선 알고리즘 같은 경우, 먼저 원본이미지에서 stride = 2로 downsampling 연산을 한다. 그 다음 kernel = 7인 convolutional filter을 진행하는데, vertical Gaussian derivative...??? 이라는 방법을 사용한다. (솔직히 뭔지 잘 모르겠다... ㅎ) 이 두 단계에서 나온 feature map으로 원본 이미지의 좌표와 비교를 했을 때, 1/4의 image position에 대한 response만 얻은 것을 확인할 수 있다. 반면 모든 image position에 filter "with holes"를 사용해서 원본 이미지의 해상도로 convolve 한다면 (stride = 2로 upsampling을 진행한다면) 우리는 holes가 없는 부분 (0이 아닌 부분)만 계산 하면 된다. 그렇기에 filter parameter 및 연산 개수는 유지된다.
빨간선 알고리즘처럼 atrous convolution을 층마다 사용하면, 최종 DCNN network response를 높은 해상도에서 확인할 수 있다. 예를 들어 VGG-16이나 ResNet-101 네트워크의 feature response에서 spatial density를 2배 증가시키고 싶다고 할 때, 우리는 먼저 해상도를 줄이는 마지막 pooling/convolutional layer을 찾는다. 그 다음 signal decimation을 막기 위하여 stride = 1로 설정하고, 그 이후의 convolution layer을 atrous convolutional layer with r = 2로 바꿔준다. 물론 비용이 많이 든다는 한계도 존재한다. 그래서 efficiency와 accuracy의 trade-off를 만족하는 hybrid approach를 사용한다. 계산된 feature map으로부터 atrous convolution을 사용하여 해상도를 4배 증가시키고, fast bilinear interpolation을 사용하여 해상도를 8배 증가시켜 원본 이미지 해상도로 복구시킨다. Bilinear interpolation은 이중선형보간법으로써, 자세한 설명을 알고 싶다면 https://en.wikipedia.org/wiki/Bilinear_interpolation 을 참조하길 바란다.
빨간선 알고리즘은 파란선 알고리즘보다 새로운 parameter을 학습해도 되지 않는 점에서 우수하며, DCNN의 속도를 향상시킬 수 있다.
또한 Atrous convolution은 어느 DCNN layer에서나 임의로 filter의 field-of-view를 증가시킬 수 있게 한다. SoTA DCNN들은 주로 3*3과 같은 작은 convolutional kernel들을 사용하여 연산과 parameter의 개수를 최소한으로 한다. 만약 rate가 r인 atrous convolution이 있다면, 그 filter값들 사이에는 r-1개의 0들이 있다. 이것은 filter의 kernel size를 연산이나 parameter 개수의 증가 없이 ke=k+(k-1)(r-1) 개로 증가시켜주는 역할도 한다. Field of view가 낮으면 정확한 localization이 가능하고 높으면 context assimilation이 가능한데, 우리는 이 두 개를 가장 잘 만족시킬 수 있는 ke값을 찾는다.
Atrous Convolution을 실행하는 방법은 두 가지가 있다.
1. Filter사이에 0을 넣어서 upsample을 하는 방법이다. 다르게 말하여 input feature map을 "sparsely sample"한다고 해석해도 되겠다.
2. input feature map을 atrous convolution rate r로 subsample한 다음, deinterlace의 과정을 통해 r2만큼 축소된 resolution map을 얻는다. 그리고 이 intermediate feature map에 standard convolution을 하는 과정에서 reinterlace를 하여 원본 이미지 해상도로 복구시킨다. DeepLab의 Tensorflow Framework에는 이 방식이 사용된다.
*Interlaced란?
Interlaced란 아래와 같이 두 필드가 하나씩 번갈아가면서 하나의 이미지로 합쳐지는 방법이다.

잘은 모르겠지만, 대충 deinterlace를 사용하여 input feature map을 r2크기로 subsample한 다음 그것을 다시 interlace 해주었다... 정도로 생각해보았다. (확실하지 않다)
3.2 Multiscale Image Representations using Atrous Spatial Pyramid Pooling
DCNNs들은 다양한 크기의 object을 input으로 받아 학습하는 방식으로 scale을 극복하는 방식으로 이루어지고 있었다. 그러나 object scale을 직접 조정하는 방식으로 크고 작은 물체들을 더욱 효과적으로 확인할 수 있도록 한다. Semantic segmentation에서 scale을 다양하게 하는 방법은 2가지이다.
첫 번째는 standard multiscale processing이다. 기존 DNN score map에서 원본 이미지로부터 연산을 공유하는, 병렬적인 여러 rescaled version들을 만들어내어 계산한다. 최종 결과값을 내기 위해서는 bilinear interpolation을 사용하여 scale들마다의 최대 response를 받아 원본 이미지 크기로 fusing을 한다. Multiscale processing은 성능을 매우 증가시키지만, 모든 scale들 마다의 연산을 해야한다는 단점이 존재한다.
두 번째는 R-CNN spatial pyramid pooling에서 착안한 "Atrous Spatial Pyramid Pooling(ASPP)"이다. ASPP는 여러 병렬적인 atrous convolutional layers를 만든 다음 sampling rate을 다르게 한다. Atrous convolution layer을 통과한 각각의 feature들은 fuse되어 하나의 최종 결과를 만들어낸다. DeepLab에는 이 방식이 사용된다.

3.3 Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
Localization accuracy랑 classification performance는 DCNN에서 서로 대립되는 요소이다. DCNN의 깊이가 깊어지고, max-pooling layer들이 증가하면 classification에서 좋은 성과를 내지만, 그에 따라 invariance도 높아지기 때문에 localization이 제대로 이루어지지 못한다. 경계를 제대로 묘사하지 못하기 때문이다. 과거에는 localization을 해결하기 위하여 여러 convolution layer의 정보를 조정하거나, super-pixel representation을 사용하였다.
DeepLab은 Fully-Connected CRF를 사용하여 localization accuracy를 증가시킨다. 정확한 semantic segmentation을 할 수 있고 기존의 방법들보다 물체의 영역을 더욱 정교하게 파악할 수 있다. 과거에는 short-range 및 local-range CRF를 사용하여 weak classifier들의 잘못된 예측을 조정해주는 역할을 하였다. 그 중 local-range CRF는 localization을 short-range보다는 높여주지만 discrete optimization problem에 있어서 높은 비용을 요구한다.
Fully-connected CRF 모델은 energy function을 사용하는데, 그 식은 아래와 같다.

먼저 E(x)부분의 x는 pixel에 대한 라벨링 분류라고 생각하면 편하다. 이 식은 두 항으로 나누어져 있다. 첫 번째 항(unary potential) 은

의 꼴로 이루어져 있는데, 이것은 DCNN에서 연산하는 특정 픽셀 i에서의 label assignment 확률이다.
두 번째 항 (pairwise potential)은 각 이미지 픽셀이 하나로 합쳐졌을 때 물체 및 그 위치에 대한 추론을 효율적으로 해준다. 그 식은

이다. 여기서 xi≠xj일 때 μ(xi, xj) = 1로, 그 외는 모ㅌ두 0의 값을 취하도록 하면서 같은 픽셀끼리는 서로 연산이 불가능하도록 한다. 괄호 안의 두 항은 두 개의 Gaussian kernel을 다른 feature space에 사용한다. 첫 번째 'bilateral kernel'은 픽셀의 위치(p로 나타냄)와 RGB색깔(I로 나타냄)을 기반으로 조정되고, 두 번째 kernel은 픽셀의 위치만을 기반으로 조정한다.
σα, σβ, σγ는 Gaussian kernel의 scale을 조정한다. Bilateral kernel은 유사한 색깔 및 위치를 가진 픽셀들이 비슷한 라벨을 가지도록 하고, 두 번째 kernel은 smoothness을 요구할 때 위치적 가까움이 충족되었는지 고려한다. Fully Connected CRF의 energy function은 Gaussian꼴의 kernel 때문에 확률적 추론이 효율적으로 이루어지도록 한다.
CRF의 효과를 살펴보려면 아래 이미지를 보아라.

4. Experimental Results
- DeepLab은 imagenet-pretrained VGG-16 / ResNet-101 네트워크를 fine-tuning하여 semantic segmentation에 적용한다.
- Loss Function으로 Cross-Entropy Loss를 사용한다.
- 모든 라벨들은 동등한 weight을 지니고 있다. (unlabeled pixel 제외)
- Optimization 방법은 standard gradient descent를 사용한다.
- 모델의 성능을 PASCAL VOC 2012, PASCAL-Context, PASCAL-Person-Part, Cityscapes에서 확인한다.
4.1 PASCAL VOC 2012
PASCAL VOC 2012 데이터셋은 20개의 object class와 하나의 background class로 이루어져 있다.
1,464개의 training set, 1,449의 validation set, 1,456개의 test set이 pixel-level 이미지의 형태로 있다. 추가적으로 data augmentation을 통하여 10,582 training이미지를 얻었다.
성능은 21개의 class에 대한 IOU로 확인하였다 .
4.1.1 Results from our Conference Version
Conference Version에는 imagenet에서 pre-trained한 VGG-16 network를 사용한다.
20개의 이미지를 mini batch로 사용하였다.
초기 learning rate는 0.001로 하되 2000 iteration 마다 0.1씩 곱하였다.
Momentum은 0.9, weight decay는 0.0005로 설정하였다.
w2와 σγ 값은 3으로 설정하였고, 최적의 w2, σα, σβ 값을 찾기 위해 validation을 통하여 조정한다.
kernel size를 낮추고 atrous sampling rate를 높일 수록, 그리고 CRF를 적용했을 때 mean IOU performance가 증가하는 것을 볼 수 있다. 아래 표에서 3*3 kernel이랑 atrous sampling rate을 12로 설정한 모델을 DeepLab-LargeFOV라 한다.

Test Set에서 DeepLab-LargeFOV는 70.4 mean IOU performance를 얻었다.
validation set의 결과는 아래처럼 시각화할 수 있다.

4.1.2 Improvements After Conference Version of this Work
Conference version 이후 DeepLab 모델은 3가지 개선사항을 거쳤다.
1. Learning Rate Policy: 기존의 "step" policy에서 "poly" learning rate policy를 도입하였다. "poly" learning rate는 learning rate을 (1-iter/max_iter)power로 곱한다. 여기서 power의 값은 0.9이며, step policy에 비하여 1.17% 높은 performance를 보여준다. 특히 batch size를 줄이고 iteration의 개수를 높여줄수록 좋은 효과를 보인다.

2. Atrous Spatial Pyramid Pooling: 앞서 언급한 ASPP기법을 아래 이미지와 같이 적용하였다.

모두 3*3 kernel을 사용하지만 atrous sampling rate r을 병렬적으로 달리하였다. 이는 다른 크기의 물체를 검출하기 위함이다. 그리고 ASPP를 사용할 때 높은 rate r = {6, 12, 18, 24}들을 사용하는 모델(ASPP-L)이 낮은 rate r = {2, 4, 8, 12}를 사용하는 모델(ASPP-S)보다 높은 성과를 내었다.

시각화는 아래와 같이 할 수 있다.

3. Deeper Networks and Multiscale Processing: 이것을 하기 위해서는 imagenet의 ResNet으로 pretraining을 진행하였다. 그리고 atrous convolution을 사용하였다.
또한 (1) 0.5, 0.75, 1의 비율로 multi-scale input을 하고, (2) MS-COCO로 pretrain을 하고, (3) input image를 0.5~1.5배 사이로 scaling하여 data augmentation을 진행하였다.
(1), (2), (3), ASPP, CRF까지 다 한 모델의 mean IOU performance는 77.69를 보였다. 추후 dataset에서도 이 모델이 가장 좋은 성능을 보인다.

Test Set에서는 79.7 mean IOU performance를 보이며 SoTA result를 얻었다.

4.2 PASCAL Context
Pascal-Context는 물체 및 배경에 대한 semantic label들이 모두 있다. 하나의 background category와 59개의 class들이 있는데, 여기서도 앞서 언급한 최고의 모델을 적용해 SoTA result를 얻었다.
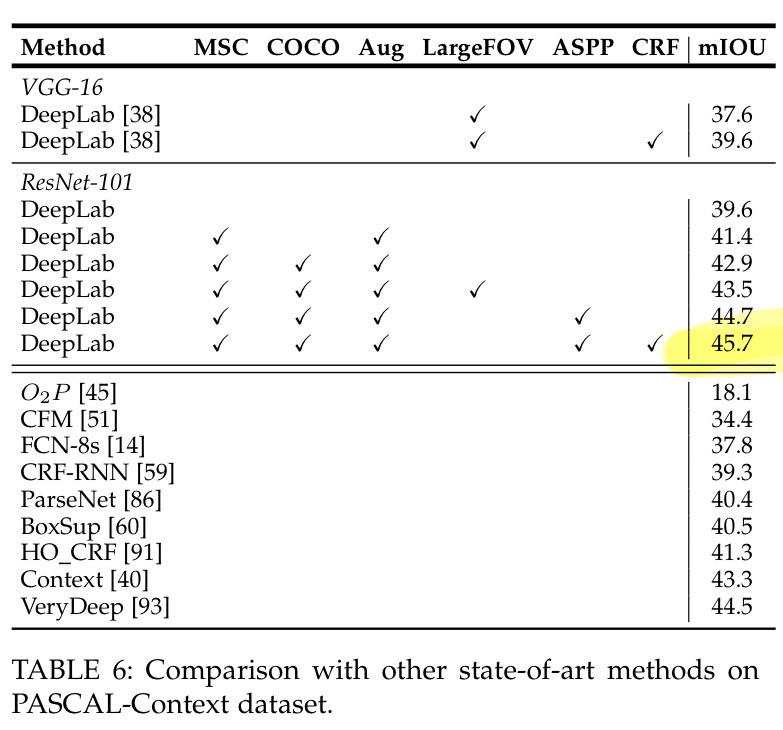
시각화는 아래와 같이 할 수 있다. 앞서 언급하였듯이 배경에 대한 semantic segmentation도 이루어졌음을 확인할 수 있다.

4.3 PASCAL-Person-Part
PASCAL-Person-Part는 사람의 신체를 머리, 몸통, 윗팔/아랫팔, 윗다리/아랫다리로 구분하고 하나의 배경 class를 출력한다. 여기서도 DeepLab가 최우수 성적을 낸다.

시각화는 아래와 같이 할 수 있다.

4.4 Cityscapes
도시에 대한 19 semantic label(및 7개의 super category: 땅, 공사, 물체, 자연, 하늘, 사람, 차량)으로 이루어진 dataset이다. 마찬가지로 최고 성능을 내었다.

시각화는 아래와 같이 할 수 있다.

4.5 Failure Modes
그러나 DeepLab도 한계가 존재한다. 아래처럼 자전거나 의자같은 얇고 segmenation이 어려운 물체 같은 경우, CRF를 적용해도 그 영역을 제대로 파악할 수 없다. 이는 unary term이 충분하지 않다는 의미로도 해석할 수 있다.

출처: https://arxiv.org/pdf/1606.00915.pdf
'AI > 논문 Review' 카테고리의 다른 글
| [논문 리뷰]FA-GAN: Fused Attentive Generative Adversarial Networks for MRI Image Super-Resolution (1) | 2021.09.28 |
|---|---|
| [논문 리뷰]Explaining and Harnessing Adversarial Examples (0) | 2021.08.18 |
| [논문 리뷰] Fast R-CNN (0) | 2021.08.02 |
| [논문 리뷰]Transformer: Attention is All You Need (0) | 2021.07.26 |
| [논문 리뷰]Alexnet- Image Classification with Deep Convolutional Neural Networks (0) | 2021.07.24 |



