
[논문 리뷰]Transformer: Attention is All You Need 본문
1. Introduction
언어 모델링, 기계 번역 등의 영역에서는 RNN(Recurrent Neural Network), LSTM(Long Short-Term Memory), Gated RNN 등이 주로 활용되어 왔다. 또한 attention을 활용하여 RNN의 성능을 더욱 극대화시켰다. 그럼에도 한계는 존재하였다. 2017년에 발표한 Transformer은 RNN을 제외하고 attention으로만 작동한다. 그럼에도 RNN보다 월등한 성능을 보였다. 그 이유는 바로 효율적인 병렬처리 때문인데, 이에 대한 것은 글을 써내려가면서 상술할 예정이다.
2. Background
기존의 ConvS2S, Bytenet 등 많은 프레임워크는 sequential computation을 활용하였다. 하지만 input position과 output position의 거리가 먼 경우에는 서로의 연관성이 떨어지기도 했고, 연관성을 증대시키자니 비용이 증가하는 단점이 존재했다. Transformer은 일정한 수의 연산을 진행한다.
Self attention은 attention의 한 종류이다.
그 전에 Attention이란 무엇일까? Attention을 이해하기 위해서는 아래 예를 살펴보자.
"He has brown hair" 이라는 말을 한국어로 번역한다고 치자.
이때 '머리'라는 token을 디코딩 할 때, 영어 문장 내에서 hair이라는 단어가 가장 중요할 것이다.
그러므로 hair에 attention을 주어 그 중요도를 높여준다.
Self attention의 유용한 예는 아래와 같다.
"She ate the bread because it was delicious"라는 문장이 있다고 치자.
우리는 "it"이 가리키는 단어가 "bread"라는 것을 직관적으로 알 수 있다.
그러나 컴퓨터는 해당 사실을 알 수 없다. 그렇기에 attention을 주어 bread에 초점을 더 주도록 만들어야 한다.
Self-attention은 특히 독해, 추상적 요약 등의 분야에서 사용한다. Transformer은 self-attention을 사용하는 첫 transduction model이며, sequence aligned RNN 및 convolution을 사용하지 않았다. 이에 대한 자세한 설명은 후술하도록 한다.
3. Model Architecture
대부분의 neural sequence transduction model에는 인코더(encoder)와 디코더(decoder)가 존재한다. 인코더는 특정 input (x1, x2, ... ,xn)을 통하여 z = (z1, z2, ... , zn)을 생성한다. 그 다음 디코더는 z를 가지고 출력값 (y1, y2, ... ,yn)를 돌려준다. 그리고 이런 모델은 auto-regressive하다고 할 수 있는데, 특정 출력값을 생성할 때 기존의 input값에 영향을 받는다는 것을 의미한다. Transformer도 마찬가지로 이런 모형을 따른다. Self-attention 및 pointwise fully connected layers는 인코더 및 디코더에 아래와 같이 존재한다.

3.1 Encoder and Decorder Stacks
인코더: 인코더는 6개의 동일한 layer로 구성되어 있다. 각각의 layer에는 sublayer이 있는데, 이 sublayer은 multi-head self-attention mechanism과 simple, positionwise fully connected feed-forward network로 구분된다. 두 개의 sublayer에는 각각 residual connection과 layer normalization이 있다. 그러므로 sublayer을 통과할 때마다 결과값으로 LayerNorm(x + Sublayer(x)) 를 출력한다. Residual connection을 용이하게 하기 위하여 출력값의 차원은 dmodel = 512 로 고정한다.
디코더: 디코더는 인코더와 마찬가지로 6개의 동일한 layer로 구성되어 있다. 다만 세 개의 sublayer이 있는데, 인코더와 같은 두 sublayer에다가 인코딩 값에 대한 multi-head attention이라는 sublayer 하나를 추가한다. 모든 sublayer에는 residual connection과 layer normalization이 있다. 또한 self-attention이 있는 sublayer에 masking을 진행한다. Masking을 하는 이유는 decoder의 출력값에는 항상 순서가 존재하는데(예를 들어 문장을 구사하기 위해서는 주로 주어 + 목적어 + 서술어라는 순서가 존재한다), 특정 position i에서의 출력값이 i 이전의 값들에게만 attention을 주도록 하기 위해서이다.

3.2 Attention
Attention function은 query를 통해서 key랑 values값을 맵핑하는 것이라 생각하면 편하다. query(Q), keys(K), values(V)는 모두 벡터 형태이다. 최종 출력값은 values에 key랑 query의 유사도로 이루어진 가중치를 곱한 것이다.
Query, Keys, Values에 대한 상세한 정의는 아래와 같다.
- Query: 영향을 받는 단어
- Keys: 영향을 주는 단어
- Values: 영향에 대한 가중치
3.2.1 Scaled Dot-Product Attention
Scaled Dot-Product Attention의 input에는 dk 차원의 query랑 key 행렬 및 dv차원의 values 행렬이 있다. 그 다음 query랑 key의 행렬곱을 하고 √dk 로 나누어준다. 최종적으로 그 값에 softmax function을 적용한다. 이것이 바로 values에 대한 가중치이다. Attention은 가중치와 values를 곱한 것이다. 아래의 식을 보면 이해가 용이할 것이다.

Additive attention이라는 것도 존재하지만, dot-product attention이 실제로 더 빠른 결과값을 출력한다. 여담으로 우리가 "Scaled" dot-product attention이라고 하는 이유는 √dk로 나누어주는 행위 때문이다. √dk가 없다면 Q와 K의 곱이 너무 커져 softmax function을 통과할 때 gradient의 값이 작아져버리는 문제가 발생한다.

3.2.2 Multi-Head Attention
dmodel차원의 queries, keys, values를 설정하여 하나의 attention function을 진행하는 것보다 queries, keys, values에 다르게 학습된 h개의 linear projection을 설정하는 것이 더욱 좋다고 한다. 식을 먼저 살펴보면 이해가 편리할 것이다.

이 논문에서는 8개의 다른 linear projection을 진행한다. 각각의 queries, keys, values에 linear projection을 진행한 값에 attention function을 통과시킴으로써 하나의 heads를 생성한다. 상술하였듯이 8개의 다른 linear projection이 있기 때문에 8개의 heads가 생성될 것이다. 이 heads는 concatenate된 후에 또 한 번 projection을 거친다.
본 논문에서는 dk=dv=dmodel/h = 512/8 = 64로 설정하였다. 그러나 이것이 필수적인 것은 아니라고 한다. 행렬 차원의 변화는 아래 이미지를 참조하자.

Multi-head Attention의 전반적인 구조는 아래와 같다.

3.2.3 Applications of Attention in our Model
Transformer은 Multi-head attention을 3가지 다른 방법으로 사용한다.
- "encoder" 층에는 self-attention layer들이 있다. "self" attention인 이유는 모든 keys, values, queries가 인코더의 직전 층에서 연산된 결과값이기 때문이다. 후술할 2번의 경우 queries는 이전의 디코더 층, keys랑 values는 인코더에서 불러들이기 때문에 "self"-attention이라고 할 수 없다. 어쨌든 i번째 layer의 output을 구하고자 할 때 이전 layer의 포지션에 attention을 가할 수 있다.

- "decoder"층에는 masking이 진행된다. Masking을 하는 방법은 다음과 같다. i번째 position에 대한 attention을 구하는 경우, 그 이후에 있는 position들에 대한 softmax function의 input 값을 -∞로 설정하여 attention의 영향을 없앤다.

- "encoder-decoder"층에서 queries들은 이전의 디코더 층에서 불러들이고 keys와 values는 인코더의 결과값이다. 그러므로 decoder은 input sequence의 모든 포지션들을 살펴볼 수 있다. 구체적으로, "decoder"층에서는 이미 masking을 통하여 query, 즉 조건을 형성하였다. 그 조건 내에서 출력될 수 있는 값들을 encoder의 결과값인 keys와 values로 확인하는 것이다.

3.3 Positionwise Feed-Forward Networks
알다시피 모든 encoder 및 decoder layer에는 fully connected feed-forward network가 존재한다. 그 구조는 다음과 같다.
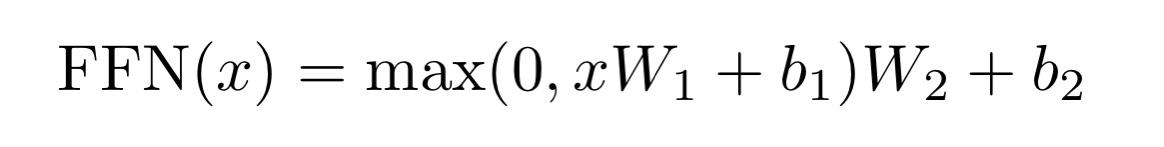
한 문장으로 요약하자면, 두 개의 선형변환이 있으며 두 선형변환 사이에 ReLU activation function이 있는 구조이다. 다르게 말하면 kernal size 1인 convolution layer이 2개 있는 꼴이다. 각 encoder 및 decoder의 layer마다 사용된 parameter들은 다르게 구성되었다. 다만 위와 같은 구조는 유지하고 있다.
3.4 Embeddings and Softmax
다른 sequence transduction 모델처럼 transformer도 input tokens와 output tokens들이 dmodel 차원으로 형성된다. 또한 학습한 선형변환 및 softmax function으로 다음에 올 token의 확률을 확인한다. Input 및 output의 embedding layer랑 pre-softmax linear transformation에 있는 weight들은 서로 공유되며, embedding layer에 있는 가중치들은 √dmodel.을 추가적으로 곱한다.
3.5 Positional Encoding
Transformer은 RNN이나 convolution이 없다. 이 둘은 모델에 특정 '순서'를 부여하는 중요한 역할을 하곤 했다. 그러므로 attention만으로 순서를 만들기 위하여 encoder 및 decoder 스택에 positional encoding을 도입한다. 이를 통해 token의 상대적/절대적 위치를 파악할 수 있다. Positional encoding과 embeddings는 같은 dmodel차원이며, 이 두 값은 더해진다. 그림을 보면 이해가 편리할 것이다.

Positional encoding에는 여러 방법들이 있지만, transformer에는 아래와 같은 방법을 사용한다.

왜 이런 식이 도출되었는가를 자세히 살펴보기 위해서는 여기를 참조하기 바란다. 이 글에서는 조금 직관적인 방식으로 positional encoding을 설명하고자 한다.
앞서 pos = position, i = 차원이라고 하였는데, pos란 input sentence에서 임베딩 벡터의 위치를 의미하며, i란 임베딩 벡터의 차원(transformer 같은 경우 512)이다. 각 i가 짝수일 때는 sin함수, 홀수일 때는 cos함수를 사용하여 input sentence에 특정 순서를 부여한다.
예를 들어 "My friend came over to my house" 라는 문장이 있을 때, my라는 단어를 두 번 사용한다.
이때 각 my의 pos는 다르다. 그러므로 positional encoding을 진행할 때 pos에 따라 임베딩 벡터의 값은 다르게 들어갈 것이며, 그로 인해 순서 또한 부여될 것이다. 실제로 20개의 단어로 이루어진 문장에 대한 positional encoding을 진행한 결과를 아래 이미지를 통해 확인하도록 하자.

중간을 기점으로 왼쪽은 sin함수에 대하여 생성된 positional encoding이며, 오른쪽은 cos함수로 인해 생성된 것이다. 이 두 값들은 연결되어 하나의 positional encoding vector로 통합된다. 실제 i = 4인 예시를 살펴보면 아래와 같은 값이 도출되는 것을 확인할 수 있다.

4. Why Self-Attention
Self-Attention이 사용되는 이유는 3가지이다.
- 레이어 당 계산량이 줄어든다. (n=sequence length 은 d=representation dimensionality 보다 작다)
- 병렬처리 연산이 용이하다. 이는 number of sequntial operations required의 최소값으로 확인할 수 있다.
- Long range dependency가 용이하다. 이는 forward signal과 backward signal이 지나가야 할 네트워크 내에서의 path length를 통해 확인할 수 있다.
이 세 가지를 정리한 표를 살펴보면 아래와 같다.

5. Training
- Dataset으로 WMT 2014 English-German dataset 및 2014 English-French dataset 을 활용하였다.
- 학습 시 8개의 NVIDIA P100 GPU를 사용하였다.
- Adam Optimizer을 사용하였고, β1=0.9, β2=0.98. ε = 10-9로 설정하였다.
- Learning rate으로는 아래의 공식을 사용하였다. 아래 공식에서 warmup_steps = 4000으로 설정하였다. Learning rate을 아래 식으로 설정함으로써 그 변화 또한 아래 그래프로 설명하고자 한다.


- Dropout 확률을 0.1로 설정하였다.
- Label smoothing을 활용하여 overfitting을 막았고, εls=0.1로 설정하였다.
결론적으로 transformer은 attention만으로 이루어진 첫 sequence transduction model이었고, 특히 번역의 분야에서 RNN 및 convolutional layers보다 더욱 빠른 속도를 보여주었다.



